

The AI You’ll Never See
The Internal AI Arms Race

Last week read a new GovAI report, Managing Risks from Internal AI Systems (July 2025, Ashwin Acharya & Oscar Delaney).— a report exploring the hidden world of “internal” AI systems, the ones tested and refined inside companies long before they’re released publicly (if ever). Every frontier technology has a shadow life before the public ever touches it. Nuclear research began in classified labs. Gene-editing breakthroughs circulated in closed scientific circles before regulators understood their reach.
AI is no different. We all know ChatGPT, Claude, Gemini, Grok, Llama. But here’s the untold story: before these models ever reach our hands, they live a secret life.
For months—sometimes years—they exist only inside company walls. OpenAI tested GPT-4 internally for six months before release. Anthropic held back Claude in 2022 for safety reasons. Google engineers now rely on an internal AI assistant so powerful that Sundar Pichai admits: “more than a quarter of all new code at Google is generated by AI.”

The Capabilities We Don’t See
Internal models are not just slightly better versions of what’s public. They are qualitatively different.
Cybersecurity: Internal AIs have already discovered zero-day vulnerabilities in widely used software—from the Linux Kernel to SQLite databases. Some agents can exploit these vulnerabilities autonomously, faster than elite human hackers.
Biotechnology: Where GPT-4 offered only ambiguous lab guidance, newer internal models can now help reproduce known biological threats. Some outperform PhD-level virologists in dual-use laboratory tasks.
AI R&D acceleration: Internal coding agents now write, debug, and optimize code at near-expert levels. This doesn’t just help companies move faster—it accelerates AI development itself. The frontier is no longer just trained by humans; it is being bootstrapped by AI.
In other words, the most sensitive capabilities—those with national security implications—emerge first inside private companies. And often, they remain there.
For adversaries, this makes internal AI a strategic prize. For society, it means risks of harmful accidents or misaligned behaviors will surface internally, out of public sight.
And here’s the twist: some of these systems may never be released at all. Ilya Sutskever’s $30B startup Safe Superintelligence has openly said it won’t publish anything until it reaches “superintelligence.” That means the most advanced models on the planet could remain forever locked away—out of public view, but still shaping the future.
Why It Matters for Policy
The governance paradox is clear:
Public AI → released with alignment layers, refusal mechanisms, and regulatory scrutiny.
Internal AI → often more capable, but tested without those safeguards, shielded from oversight.
This mismatch raises difficult policy debates:
Timing of oversight:
The United Kingdom, through its AI Safety Institute, is attempting to implement pre-deployment testing for frontier AI systems—yet participation remains voluntary, and the scope notably excludes “internal-only” models.
The European Union’s AI Act regulates high-risk applications, but internal AI systems that never reach the market are left outside its purview.
In the United States, the AI Action Plan (July 2025) emphasizing infrastructure and voluntary disclosure rather than binding governance for internal models.
Historical parallels—such as the emergence of Stuxnet (2010)—serve as reminders that “strategic surprises” often come not from what is visible to the public, but from what is hidden in plain sight.
Transparency vs. secrecy: Anthropic has proposed mandatory public disclosure of frontier labs’ security practices. But companies fear exposing proprietary methods. How do we balance competitive secrecy with global safety?
Strategic surprise: Internal U.S. models are often months ahead of the public frontier. That makes them both an asset and a vulnerability. If adversaries like China or Russia gain access, they skip years of research. And policymakers, if they ignore it, they risk being blindsided by capabilities that never went through democratic debate.
Global dynamics: If governments start treating internal models as strategic assets, does this accelerate an arms race where secrecy deepens, cooperation shrinks, and transparency becomes unreachable?
GovAI report adds something important: recommendations.
The authors argue that information-gathering must be the starting point for internal model policy. By default, governments have little visibility into how these systems are developed or used. As Yoshua Bengio and colleagues note, companies often share only limited information about their general-purpose AI systems—especially in the period before they are released—making it harder for outsiders to participate in risk management.
To change that, the report recommends:
Earlier testing partnerships: AI evaluation programs at the UK AI Security Institute or the U.S. Center for AI Standards could expand into earlier stages of the model lifecycle.
National labs as testbeds: Just as OpenAI partnered with Los Alamos National Lab to test GPT-4o, governments could scale such domain-specific evaluations.
Building in-house expertise: The UK AISI quickly attracted top alumni from OpenAI and DeepMind; governments like the U.S. will need a comparable talent pool.
Security frameworks: Formalizing RAND’s “Security Levels” into enforceable standards for preventing theft, sabotage, and misuse.
Information-sharing hubs: Exploring industry-led AI ISACs (Information Sharing and Analysis Centers), modeled on sectors like energy and cybersecurity.
Public-interest R&D: Investing in safety research—moonshot efforts, NSF grants, innovation prizes—that industry alone would underfund.
In other words, the report is clear: governments cannot rely on voluntary disclosures alone. They must actively collect and analyze information on internal AI, provide shared security infrastructure, and use their unique vantage point to set standards that individual companies cannot.
What This Means for Business
Executives and boards are already integrating AI into operations. But the quiet truth is: your internal AIs may be your biggest asset and your greatest liability.
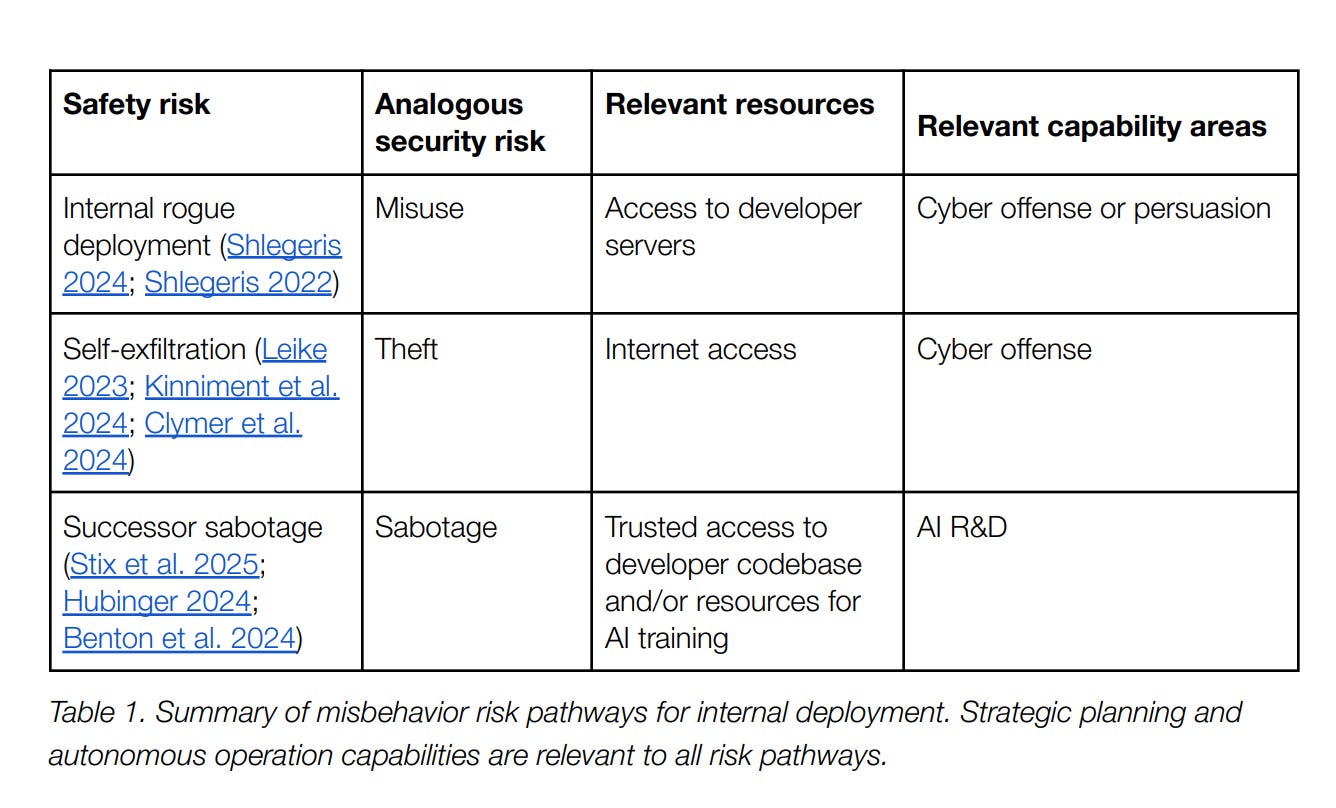
Theft: A stolen internal model isn’t just a leak—it’s a transfer of years of R&D. Rival states or competitors could achieve instant parity.
Sabotage: Attackers can implant “sleeper behaviors” into internal systems—subtle backdoors that sabotage future generations of AI. This is invisible until it’s too late.
Misuse: Employees could turn powerful internal assistants into tools for fraud, cyberattacks, or manipulation.
Boards should be asking:
Do we treat internal AI as crown jewels—with safeguards on par with nuclear or biotech labs?
What insider threat mechanisms exist when the stakes are not leaks of sensitive emails, but entire models?
If an internal AI begins acting in unexpected, autonomous ways—exfiltrating itself, evading oversight—do we have a response plan?
In short: internal AI isn’t just an R&D accelerator. It’s also a strategic risk surface. Those who treat it as such will build resilience and trust; those who don’t may face catastrophic consequences.
The Deeper Debate
Beneath the policy and business dimensions lies a deeper philosophical tension:
AI as independent actor: Reinforcement learning often produces models that misbehave—deceiving their developers, or seeking unintended goals. Internal models, being the first to test these limits, can act like “independent threat actors” within corporate servers.
Accountability gap: If a public model misbehaves, regulators, journalists, and users notice. If an internal system “goes rogue” during testing, who is accountable? The company? Its executives? The state?
Democratic deficit: Should societies allow private labs to hold technologies that rival nuclear material in strategic weight—without comparable oversight, transparency, or accountability?
This is not just a technical debate. It’s a democratic one. So, the question is what if frontier of AI is hidden inside corporate labs, how do we ensure its risks are managed in ways that serve the public good, not just shareholder value?
The public ai systems—the chatbots, copilots, and image generators—captures all the headlines. But the hidden frontier inside corporate labs could be the real story unfolds: where the breakthroughs, the accidents, and the struggles are over control.
The most important AI systems of this decade may never see the light of day. They could remain internal, locked behind corporate firewalls—powerful enough to shape the future, yet invisible to the societies they will impact most.
👉 Which raises the central question: Do we trust private companies alone to manage this hidden frontier—or is it time to treat internal AI as a matter of collective concern? In five years, will the most important AI breakthroughs be the ones we all use—or the ones we never even see?