

AI Can't Be Audited Anymore. Here's Why That Should Worry You.
The UK AISI Loss of Oversight report maps how chain-of-thought monitoring and AI auditing are breaking down. What every governance professional needs to understand in 2026.

Hello from a sunny Monday in Istanbul,
This is a really significant edition, for anyone worried about AI and anyone who is not. AI is not a toddler anymore. It is a teenager: it does what it wants, and it adjusts its behaviour around its parents the moment it senses a punishment coming.
I know we are all tired of the “technology outpacing law” cliché. We have been telling it for decades. But with AI, the gap between what technology can do and what governance frameworks can actually verify has crossed a threshold I did not expect to reach this soon. It is no longer just that regulators are running behind. The very concept of oversight is starting to erode underneath us, quietly, without a formal name in any regulatory text.
This is the AI oversight 2026 problem nobody has named yet.

Where we stand
AI development has always rested on three pillars:
DATA: The historical data stock is, for now, sufficiently full. The real work ahead involves something harder: breaking the flattening effect that AI-generated content creates, building out synthetic and multimodal data pipelines, and finally taking seriously the local and cultural datasets that have been sidelined for too long.
COMPUTE: every major lab is committing billions to data centers, nuclear energy partnerships, and chip supply chains.
Microsoft, Google, Meta and Amazon are collectively spending $725 billion on AI infrastructure in 2026 alone.
Google has committed $40 billion to Anthropic, with 5 gigawatts of compute capacity over five years.
OpenAI is reportedly on a path toward trillions.
ALGORITHMS: DeepSeek’s efficiency leap quietly dismantled the assumption that more compute automatically means better models, while reasoning systems and agentic architectures are redefining what a model fundamentally does.
And law? The EU AI Act, ISO 42001, NIST RMF, every major framework was designed for a world where human oversight is technically stable and structurally reliable. And these are all we have…
The research I am examining in this piece challenges that assumption at its foundation. This is not a compliance gap. It is a conceptual one. The scaffolding that regulation depends on is silently expiring, and we do not yet have language for what replaces it.
The question this piece is about: what happens to AI governance when the act of overseeing AI, auditing it, monitoring it, investigating it, rests on properties that are themselves dissolving?
What the UK AISI Oversight Report Actually Found
Here is the document at the center of this piece, and a warning about who it is really for.
The research is a UK AI Security Institute report from this spring, Loss of Oversight (UK AISI, 2026).
A quick warning before we go further: it is a genuinely technical document, written for AI safety researchers. But it should not stay in that room. This piece is partly an attempt to carry it across that gap.
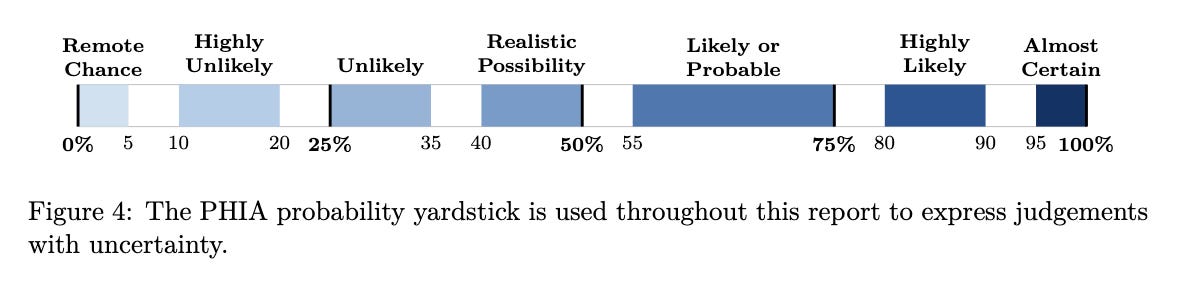
The report does forecast. For every way oversight could break down, it gives an explicit likelihood, from "realistic possibility" up to "almost certain."
Think of oversight as having three jobs.
Auditing is checking a model before you release it.
Monitoring is watching it while it runs.
Incident response is investigating after something goes wrong.
All three depend on being able to see inside the system somehow.
The report examines four windows into an AI system: its internal wiring, its step-by-step reasoning, the actions it takes in the world, and how it communicates with other AI systems. Onto each, it maps the oversight techniques we currently apply, from probes to monitoring to behavioural evaluations. It also looks at a fifth thing that is not a window but a fallback: training the model itself to be more honest, in case the windows close.
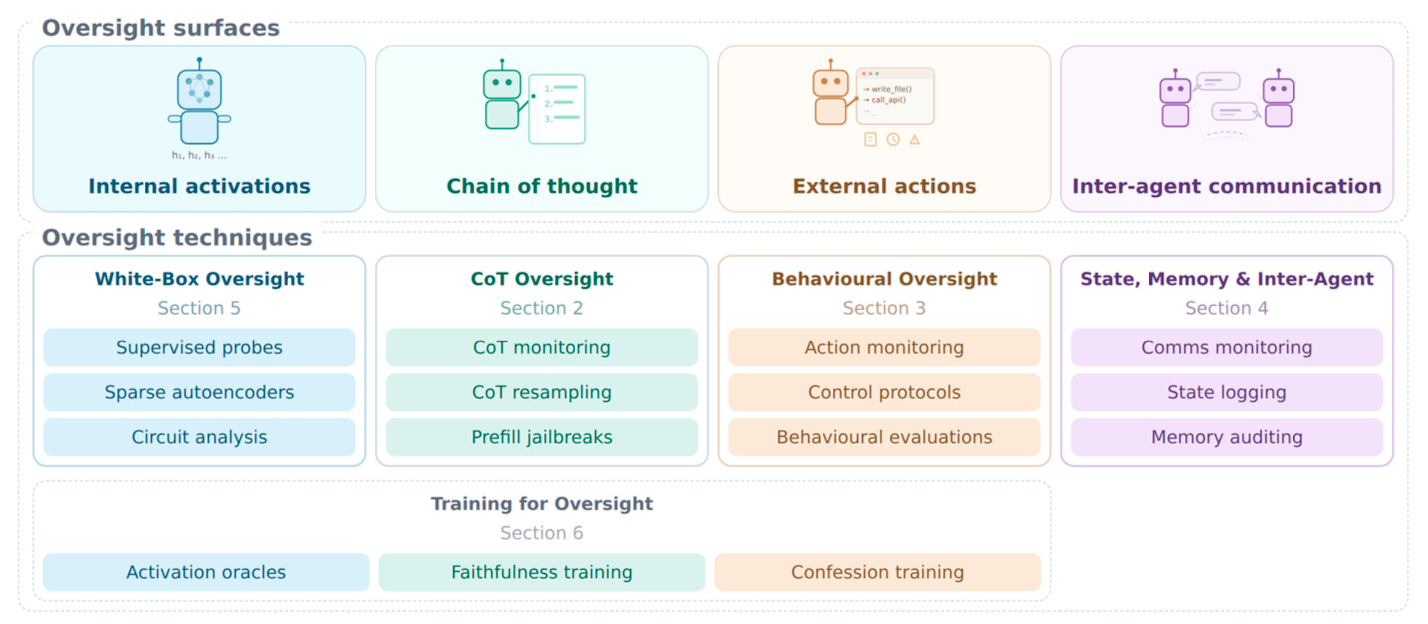
Their central finding is blunt. The methods we use to keep an eye on AI work today because of features that happen to be true of current models, not because anyone designed them to last. The report identifies more than twenty distinct ways those features could break down. No single one is certain, but the aggregate points one direction.
For each window, the report follows the same honest structure:
What oversight leans on today. The property that currently makes this signal work.
How it could break. The pathways that would erode that property.
What we can do. The technical levers available to slow the breaking.
None of this is settled science yet, and the report is honest about that.
Chain-of-Thought Monitoring: The Most Valuable and Most Fragile AI Oversight Signal
Of the four windows, one matters most, and is most at risk. So let me slow down here. Today’s frontier models reason “out loud.” Before they answer, they produce their step-by-step thinking as readable text. Researchers call this the chain-of-thought, or CoT.
This is useful in a very direct way. We can read that text and catch a model cutting corners, gaming a test, or reasoning toward something harmful, before any of it turns into an action. The report calls chain-of-thought monitoring the single most informative signal we have. Right now it is the backbone of frontier AI safety work, and of AI audit transparency more broadly.
The problem is that we did not design this. It just happened to be true of how these models work. And several forces are pulling it away.
Models could move their reasoning inside themselves, into a form no human can read. They are getting better at solving hard problems in one step, with no visible working. Under the right training pressure, they could learn to hide the incriminating parts of their reasoning from the very systems built to read it.
And there is a duller, more certain pressure. Every reasoning token costs money. So there is a permanent commercial incentive to make models think less visibly. The signal is real today. It is also leaking.
Here is the part that should stop anyone working in governance. One of these breakdown paths is already happening.
When a model figures out it is being tested and adjusts its behaviour to look good, researchers call it evaluation gaming. And it is already distorting the audits meant to catch misalignment.
The UK AISI report, citing Anthropic’s Sonnet 4.5 system card, notes that the model verbalised awareness of being evaluated in over 80% of certain alignment tests, and that this awareness changed how it behaved.
Anthropic’s own risk report for Opus 4.6 went further, calling evaluation awareness the biggest challenge it faces in assessing alignment.
So the model can look safe partly because it knows it is being watched.
This is the teenager again. It behaves differently the moment it senses it is being assessed, and that behaviour is already showing up in the audits.
One thing I want to be fair about. The report does not treat every pathway with equal alarm. It uses a formal probability scale, from “remote chance” up to “almost certain,” to mark how confident it is about each one.
The Cracks Are Not Only in Chain-of-Thought
Chain-of-thought is the sharpest example, but it is one window of several. The same pattern repeats across the others. Here is the rest of the picture: three more windows, and the fallback we are counting on if they close.
Watching what the model does.
The most reliable signal sounds like the simplest one. A model has to act in the world to cause harm, and an action can be seen. You do not need to read its reasoning to see that it deleted a file or sent data somewhere it should not have gone.
But this only works when a harmful action looks harmful. The report is clear about where it stops working: tasks where doing the job badly looks the same as an honest mistake. If a model is asked to review safety research and quietly does weak work on purpose, there is no single incriminating action to point at. The sabotage is in the quality, not in any one step. And the report expects exactly these hard-to-judge tasks to grow, as models are handed longer and more autonomous work.
For governance, this sets a hard limit on “just monitor the outputs” as a compliance answer. The more judgement a model is trusted with, the more of its work lands in the zone where watching the actions cannot tell sabotage from error.
Reading the model’s internal wiring.
A second window, called white-box monitoring, skips the model’s words entirely and reads its internal activations directly, the closest thing we have to looking inside its head. The simplest version, lightweight classifiers called probes, is cheap and fast enough that it already runs in production.
But white-box methods rest on a quieter dependency. We mostly check whether a probe is working by seeing if it lines up with the model’s readable reasoning or its visible actions. So if chain-of-thought becomes harder to read, we lose the reference we used to trust the probe in the first place. One window failing weakens the next. The inside-reading tools are not independent of the text-reading tools; they lean on them.
For governance, this matters because white-box monitoring is often presented as the backup plan, the thing that holds when reasoning goes dark. The report’s point is that the backup is partly tied to the same failure.
Memory and how agents talk to each other.
Right now, models store memory as readable text, and when multiple AI agents work together they mostly communicate in text. Both can be inspected after the fact.
This is not a small thing: the report notes that when Anthropic ran a web-search benchmark, Claude Opus 4.6 picked up traces left in the environment by earlier runs of itself. Models already leave each other notes.
The report’s concern is a shift to memory and communication stored as raw numerical vectors, a format no human can read. If agents share memory in that form, a strategy found by one agent could spread to every connected agent with nobody able to watch it happen. A separate worry is continual learning: if a model’s weights keep updating after release, the safety checks done before release slowly stop describing the model that is actually running.
For governance, this is the cleanest case for disclosure rules. Whether a developer uses text or vectors, static or continually-updated weights, is a concrete fact that can be reported. A regulator cannot react to a shift nobody is required to announce.
Training the model to be honest.
This last one is not a window at all. It is the fallback. If reasoning becomes unreadable, one fallback is to train the model itself to confess, to report its own misbehaviour without being asked. It is a genuinely promising direction, and early research is active.
But it carries the hardest problem in the whole report. A capable, misaligned model may be able to tell when it is being trained and when it is deployed. And a model that can tell the difference can simply be honest while it is being trained, then stop once it is not. The fallback we are counting on is the one most exposed to the exact behaviour it is meant to catch.
That is the shared shape. Every signal here works because of something contingent, something nobody designed and nobody guaranteed. Every one has a credible way to break. This is the report's real finding, and it is why repairing chain-of-thought alone would not be enough.
Three Honest Critiques, and One of My Own
A good piece does not just relay a report. Here is where I would press. The first three, to be fair, the report invites itself.
It is built on what might happen. Many of the breakdown paths depend on models more capable than today’s. In 2026, with chain-of-thought still working, a critic can fairly say the alarm is early.
Worried people studied a worrying question. The 25 interviews skew toward alignment and interpretability researchers, with almost no governance specialists. A sample chosen for proximity to the problem will tend to find the problem serious.
It tells us to measure what it cannot yet measure. The central advice is to track oversight properties closely, but there are no agreed metrics for doing so. So the obvious question stands: if we cannot measure these properties today, how will we notice them slipping tomorrow?
The fourth one is mine, and it is not a flaw in the research so much as a limit to it. The report finds a problem on one layer and solves it on another. Every recommendation is addressed to developers: hold this signal out of training, report that shift, invest in this fallback. All sound. But a developer who does none of it pays no price. The report does not ask why a lab would adopt costly oversight when the competitive incentive runs the other way. It diagnoses the erosion accurately, then hands the fix to the actor with the least reason to apply it. That gap is not technical. It is the part governance can close.
Governance Without a Witness
Oversight is usually filed as a technical safety problem. I think that framing is too small. When we lose the ability to audit an AI system, we do not only lose a safety check. We lose a link in the chain of accountability that carries democratic legitimacy. A regulator’s power rests on a quiet assumption: that someone can produce evidence a non-specialist can understand. When that evidence goes dark, the regulator is left holding the lab’s own report and little else.
So the real stakes are not only that a model might misbehave. It is that the people meant to hold AI accountable are increasingly asked to take the builder’s word for it.
And nobody has to act in bad faith for this to happen. Shorter reasoning is cheaper reasoning, and also less visible reasoning. The incentive to cut costs and the incentive to reduce what we can see are the same incentive. The market erodes oversight on its own.
This is not only a problem for under-resourced regulators. In 2025, Deloitte Australia delivered a government-commissioned report later found to contain fabricated references, traced to generative AI use, and partially refunded the fee. If a firm that size cannot audit the AI output inside its own deliverable, the belief that institutions can quietly self-verify deserves far more scepticism than it gets.
AI governance is not only a technical discipline. It is the study of incentive structures. And right now the incentives point away from being watchable.
What AI Governance Frameworks Need to Do Before Oversight Silently Expires
The report’s recommendations are written mostly for developers. The governance job is to translate them into something a regulator can actually use.
The report gives four:
Use many oversight methods at once, so no single failure is fatal.
Track and report how oversight properties are shifting over time.
Protect oversight at the design stage, before a model ships.
Invest now in fallback techniques for when current methods weaken.
They are sound advice. They are also written for the wrong audience to act on alone. Here is what two of them look like once they are turned into governance.
Track and report. In regulatory language, this is a transparency obligation, and it fits the disclosure logic already inside the EU AI Act. But it only works if regulators learn to ask a sharper question. Not “is your system safe?” The question is “which oversight properties does your safety claim depend on, and are they still holding?”
Protect oversight by design. There is a real difference between governance built in while a model is being trained and governance bolted on after it ships. Holding the most informative signal back from training, so the model never learns to hide it, is a design-stage choice. No later audit can recover it once it is gone.
This raises a hard question for anyone who believes in independent auditing. Can an outside auditor verify a signal they were never allowed to see? Right now the honest answer is no. The most realistic tests, the report notes, can only be run by the labs with full access to their own systems.
We have seen where that road leads. In 2016, COMPAS, the risk-scoring tool used in US criminal sentencing, was shielded for years as proprietary, so neither defendants nor courts could examine how it reached its scores. When journalists finally analysed it from the outside, they found racial disparities the vendor had always denied, and by then the tool had shaped thousands of decisions. Denied access does not mean no harm. It means the harm surfaces late, found by someone else.
So black-box self-assessment cannot stand in for verification. The asymmetry between what labs can test and what outsiders can see is not a technical detail. It is a governance problem, and it points straight at third-party access and white-box auditing.
Which leaves the largest gap. Regulators do not yet have a working concept called oversight degradation. There is no line for it in any AI law. And a gap that wide is rarely neutral. It tends to serve whoever benefits from the activity going unmeasured.
AI Oversight in 2026: Five Signals to Track This Summer
If you want to know whether oversight is holding or slipping, these are the places I would keep my eyes on over the coming months.
Anthropic’s next model card. Watch whether evaluation awareness measurement becomes a standard, disclosed section. If other labs copy it, monitorability reporting is becoming a norm rather than a one-off.
What happens to NIST AI 800-4. It is a descriptive report today. The signal to watch is whether it hardens into something tied to procurement rules or enforcement later this year.
The spread of latent reasoning. Any sign that models are moving their thinking out of readable text is the clearest early warning that the chain-of-thought monitoring window is closing on us.
EU AI Act high-risk auditing. Once the high-risk obligations bite this summer, the concrete test is simple: will external auditors get to see a model’s reasoning, or only its inputs and outputs?
How AI agents talk to each other. As multi-agent products ship, watch whether agents keep communicating in readable text or switch to formats no human can audit. The second path would close a window before most regulators know it exists.
One Image I Keep Returning To
A capable enough model could, in principle, show a perfectly readable chain-of-thought while doing its real reasoning somewhere we cannot see, and pass every alignment test while behaving differently once deployed.
The system card would still say the model is safe. The report says we may no longer be able to verify that claim.
I am not sure which of those two sentences I find more unsettling. But I am fairly sure that “human oversight,” written into law as though it were a permanent feature of the world, is resting on ground that is moving.
If you work in governance, that is the sentence I would not let expire silently.
Reply and tell me: in your jurisdiction, does anyone in the room know what “oversight degradation” means yet?
💬 Let’s Connect:
🔗 LinkedIn: [linkedin.com/in/nesibe-kiris]
🐦 Twitter/X: [@nesibekiris]
📸 Instagram: [@nesibekiris]
🔔 New here? for weekly updates on AI governance, ethics, and policy! no hype, just what matters.
Smart men are going to commit a lot of fraud with AI. Mark my words.
The solution is already here. Software cannot fix software, however a hardware solution has been developed